
The Journey of a Project
One of the projects that I am currently working on in my spare time has become large enough that it now spans five Git repositories. I worked on the project for approximately 5 months in late 2020 and early 2021 before starting a full-time position as a data scientist. Past-Gavin was in the groove and had the mental flow to accommodate all the moving parts of the project while also identifying the next important steps to take. Present-Day-Gavin is not so gifted. The code is clear, but the ‘path’ leading to and from each script or function in the project is less so. Not surprisingly, I feel slightly intimidated by the project’s complexity when I consider diving back into it again.
If you have managed any project containing code and data then you have almost certainly experienced this challenge.
To Travel is to Learn
“There is only one thing more painful than learning from experience and that is not learning from experience.”
Past-Gavin had flow, but Present-Day-Gavin has the benefit of hindsight!! The pain of struggling to get the project moving forward again led me on a journey into the world of pipeline management e.g., targets (an R package) and many more. In this journey of exploration, a work project at Fathom Data required me to get familiar with dvc (Data Version Control).
In this blog post, I want to share how dvc can help us all to avoid the painful experience of coming back to an important project and feeling frustrated enough to quit immediately.
DVC
Briefly, dvc is a command line interface (CLI) tool that works like git to manage project objects i.e., large data files, model outputs or any file, that we don’t want to manage using git. While the ‘data version control’ feature was the first application I used dvc for, it is the ability to quickly create a project pipeline with dvc that seems the most useful to me now.
Conveniently, the topic of a project pipeline which streamlines the onboarding of collaborators (including our future selves) is trivially easy to demonstrate/experience for oneself.
A Journey of Simplicity
In this blog post, I offer you two experiences: 1. Dive into my dvc-pipeline-demo repo on Github (here) and follow the instructions in the README to experience the simplicity of reproducing the exact workflow and outputs that I built the repo for. 2. Continue reading this post to learn how to create a project pipeline using dvc.
Collaborating Made Simple
When you clone my repo to your local machine, you are missing many of the dependencies and outputs of the pipeline. This is not a mistake on your part. I did not push these files to the remote repo. In some cases the files that our workflow depends on may be so large that tracking them with Git is not ideal. In other cases the raw data used by our workflow may be regularly updated, thereby rendering the previous iterations of our workflow invalid.
Getting Oriented
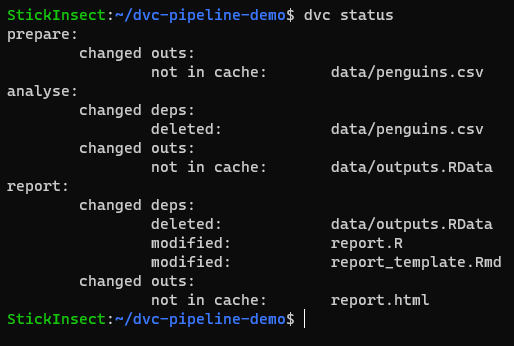
In the same way that we can use git status to check the current state of our git-tracked files, we can use dvc status to check the state of our repo in relation to the pipeline that is contained in dvc.yaml.
dvc statusThe stages of our pipeline are prepare, analyse, and report. In each stage we see the word changed followed by by either “outs” (outputs) or “deps” (dependencies). Reading line by line we see that each stage has issues with some form of missing or modified dependencies/outputs.
Running the Pipeline
To understand how dvc status works, we need to look at the dvc.yaml file located in the root folder of the repo. In your cloned repo you can run:
cat dvc.yaml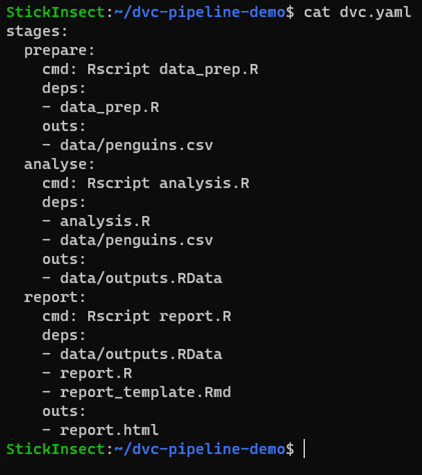
The dvc.yaml file contains our complete pipeline. Each stage is populated with a cmd (command) to execute, as well as deps which the stage requires to be present before it can execute and outs which the stage will generate upon completion of the cmd.
If we spend a few moments looking for the deps and outs listed for each stage, we will find some of them but not others. For example, data/penguins.csv and data/outputs.RData are missing, but report_template.Rmd is present/modified. This exactly matches the information that dvc status gave us.
In some cases, we might need to pull a data file from a remote storage location tracked by dvc. However, if we look closely at the prepare stage, we see that data/penguins.csv is an output of the data_prep.R script. This means that we just need to run the pipeline using:
dvc reproThen you can sit back and watch the magic…
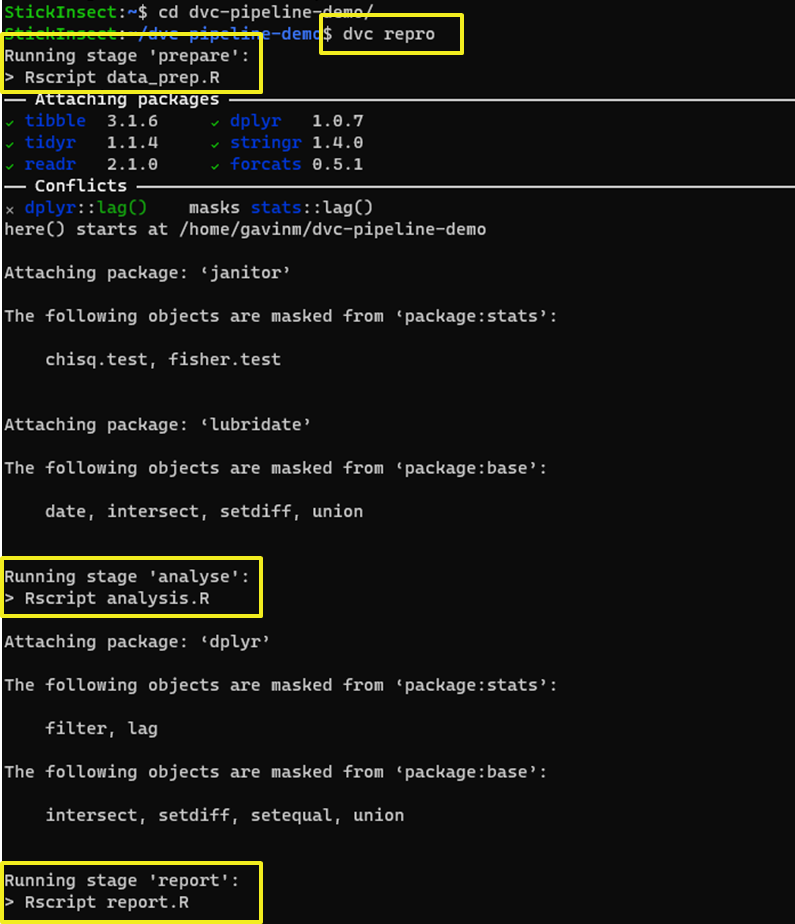
Each stage of the pipeline is executed in sequence.
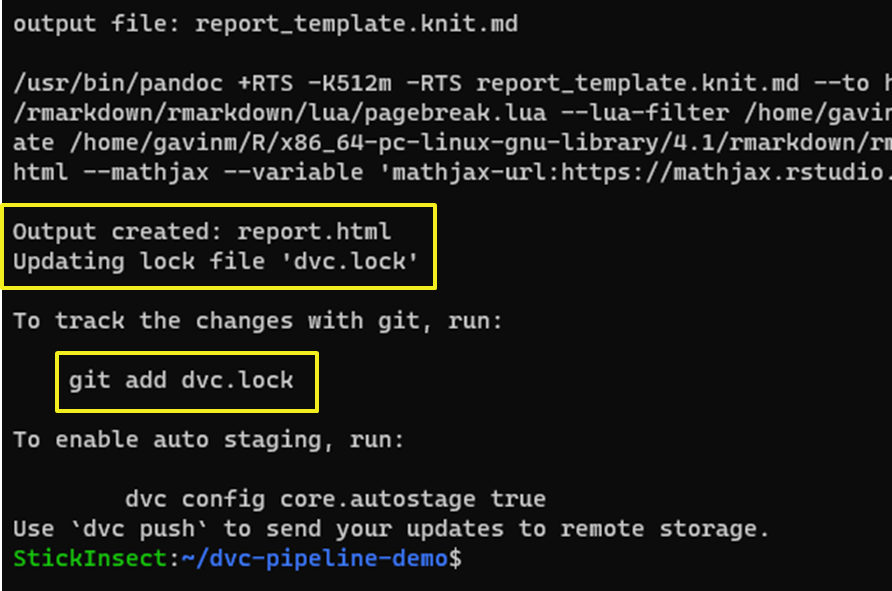
At the end of the report stage, our report.html file is created and we are told that dvc.lock has been updated.
Note: The
dvc.lockcan be tracked by git to make it easier for collaborators to know when they should rerun thedvcpipeline. Agit pullof thedvc.lockfile will tell us viadvc statusthat our repo does not contain the latest versions of thedvc-tracked files.
But.. How?
If it feels magical to be able to execute the entire project pipeline with a single dvc repro call - I completely understand. But how does it work?
In short, when we run the dvc repro command, the files tracked in the pipeline defined in dvc.yaml are compared against their state listed in the dvc.lock file.
The dvc.lock file contains an md5 hash and size information for the state of each file tracked in the dvc pipeline.
cat dvc.lock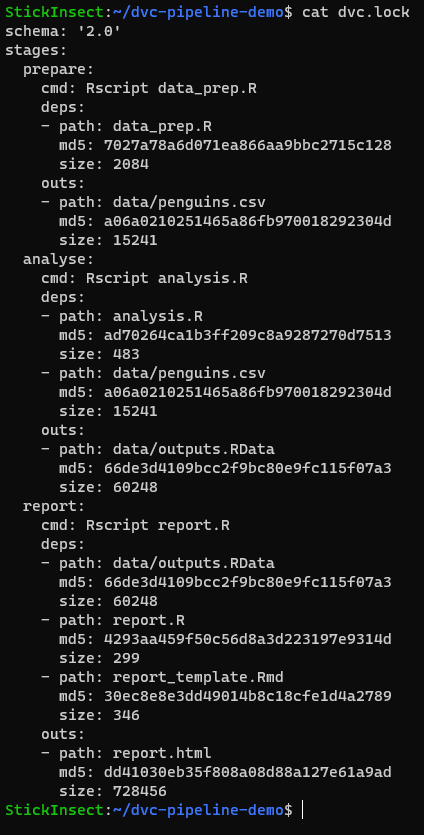
If we make changes to any of these files and run dvc status, then the file states are compared against the dvc.lock information and the output reflects any changes detected.
A Tactical Operator
One important thing to note is that dvc will only run stages that have been affected by the change. If there are stages that are unaffected, a call of dvc repro will skip the stages with unchanged deps and outs.
For example, if we delete data/outputs.RData then dvc status tells us that only the analyse and report stages have been affected.
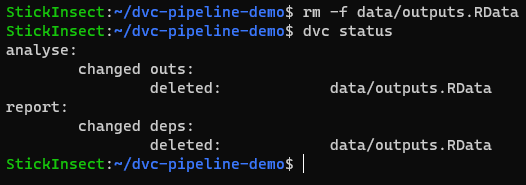
When we run dvc repro, we see that prepare is skipped, data/outputs.RData is retrieved (‘checked out’) from the dvc cache of the file to complete the analyse stage and the report stage is then also skipped because there was no change in data/outputs.RData which was used to generate report.html.
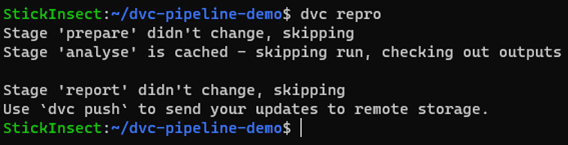
In this way, dvc is able to get your repo into working order with the minimum processor time required. That’s pretty cool, right?
Final Thoughts
dvc is a powerful CLI tool that can be used to version control large data files outside of our Git repo and manage the pipeline that processes these files in our workflow. In this post, I have focussed on the latter implementation of dvc.
If you want to have some fun, try changing / deleting lines of code from any of the files tracked in dvc.yaml. Then run dvc status and use the information provided to guess what will happen when you run dvc repro. There is no better way to see dvc in action.