Data Science with {pins}
Data Sharing in Distributed and Polyglot Settings
It’s Data-Sharing Day!
I have some data to share with you.


# python -m pip install pins
import pins
base_url = "https://gavinmasterson.com/pins"
pin_paths = {
"snake_detections": "snake_detections/20240730T195415Z-6c718/",
"snake_top_five": "snake_top_five/20240730T195447Z-2039f/",
}
board = pins.board_url(base_url, pin_paths)
board.pin_list()
# Investigate individual data sets
board.pin_meta("snake_detections")
board.pin_read("snake_detections")A Tough Choice?

A Tough Choice?
“R or Python” is a consistent search query:
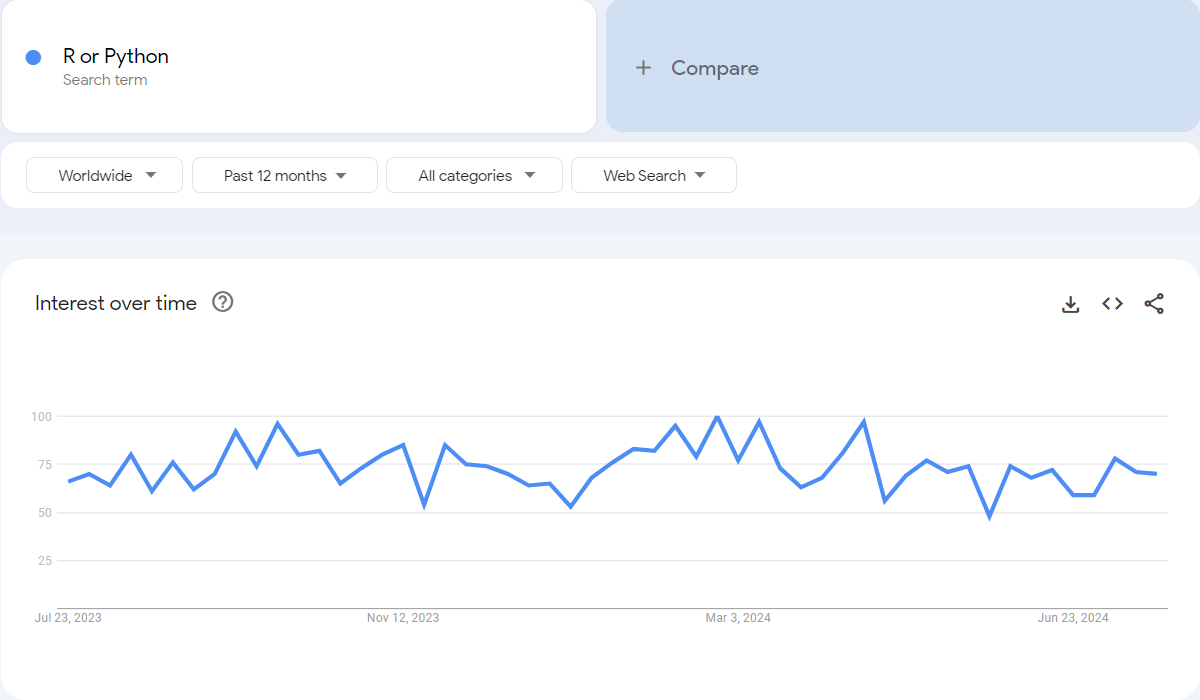
A Tough Choice?
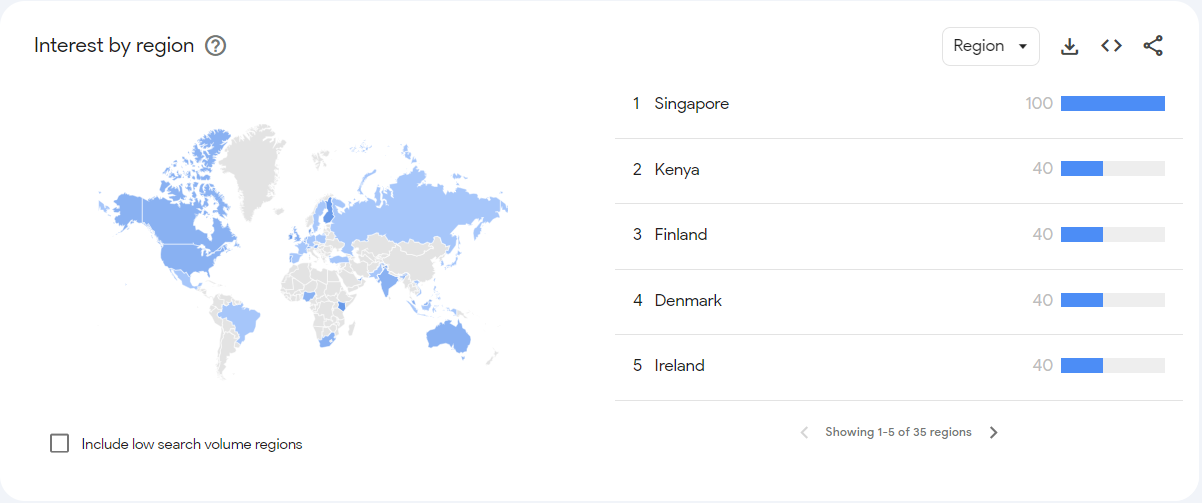
Apparently a ‘high stakes’ decision in Singapore:
Follow Along
You can run this workflow locally, with the same data that I have used.
View the Board State
To view the state of the board, we can use the following code:
Get the Pin from my board_url()
Here is the same code we used at the start of the presentation:
# python -m pip install pins
import pins
base_url = "https://gavinmasterson.com/pins"
pin_paths = {
"snake_detections": "snake_detections/20240730T195415Z-6c718/",
"snake_top_five": "snake_top_five/20240730T195447Z-2039f/",
}
board = pins.board_url(base_url, pin_paths)
board.pin_list()
# Investigate individual data sets
board.pin_meta("snake_detections")
board.pin_read("snake_detections")

