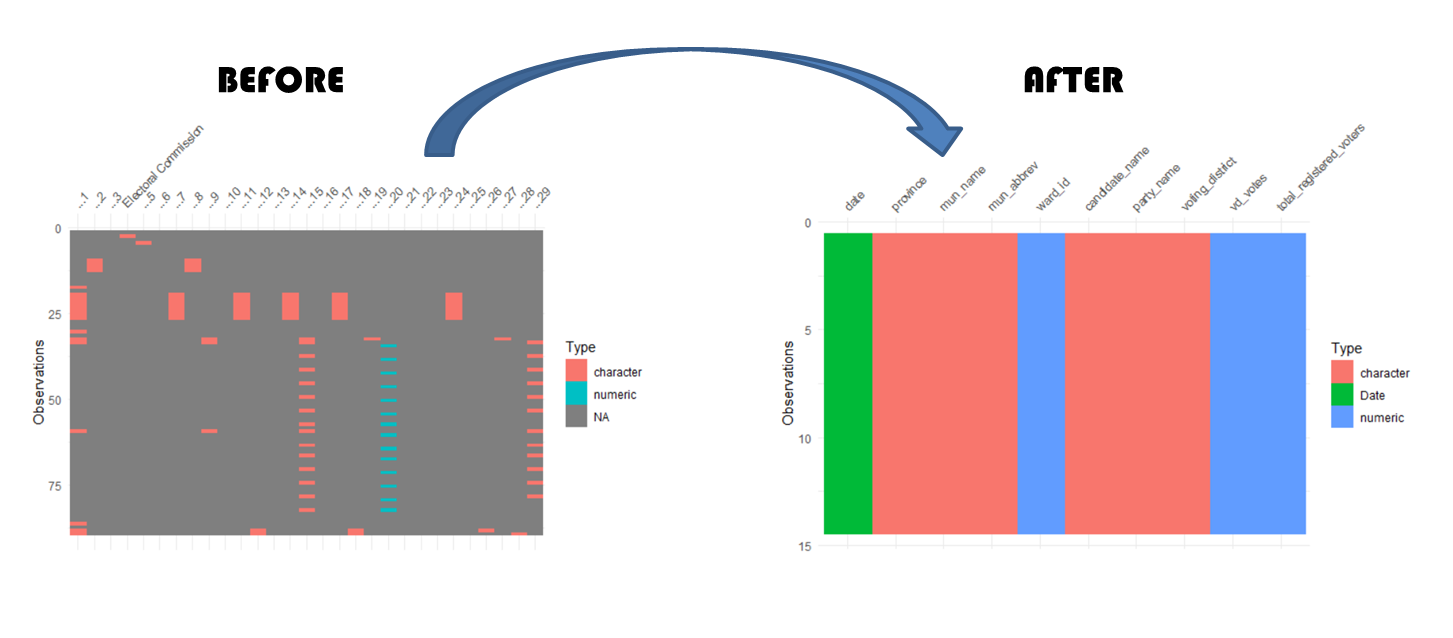
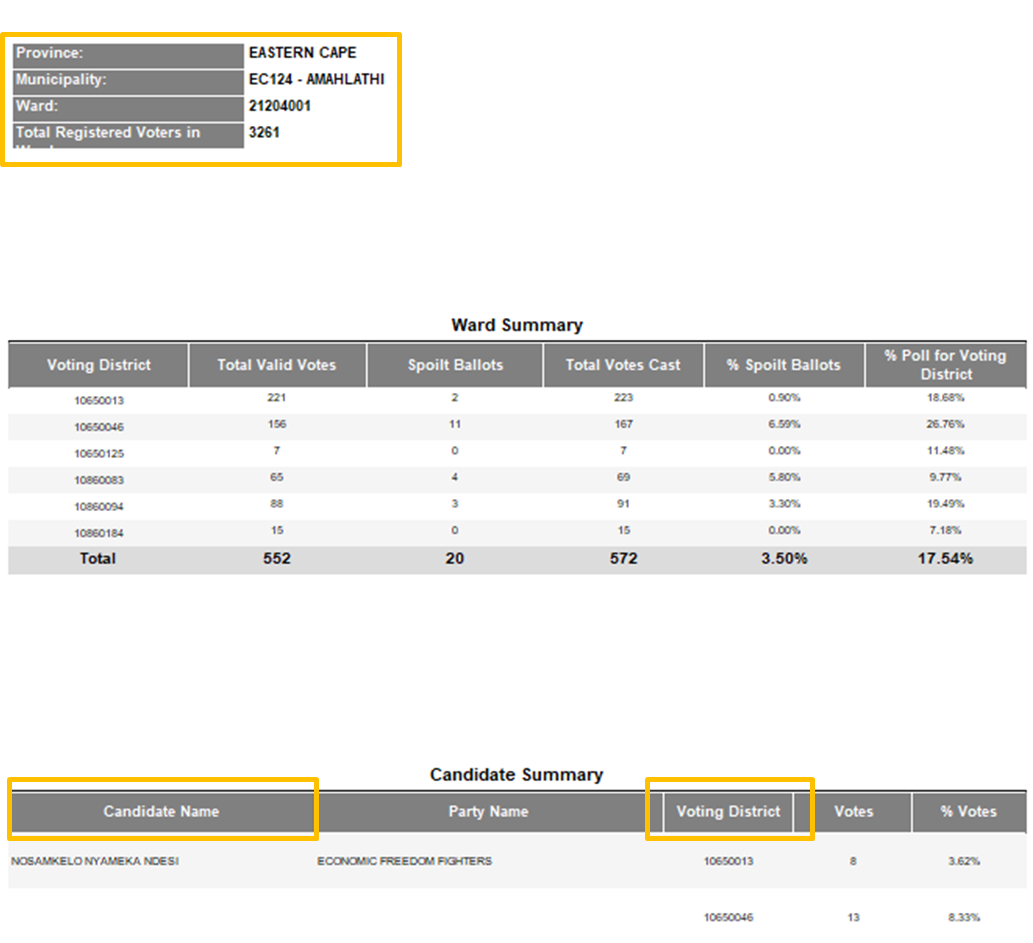
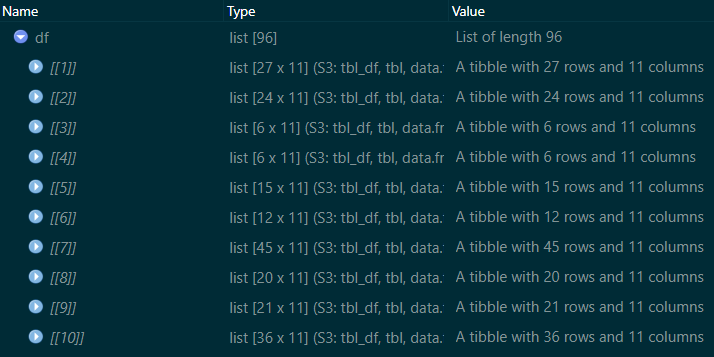
Rows: 89
Columns: 29
$ ...1 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...2 <chr> NA, NA, NA, NA, NA, NA, NA, NA, "Province:", "M…
$ ...3 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ `Electoral Commission` <chr> NA, "BY-ELECTIONS 11 Nov 2020 RESULTS REPORT", …
$ ...5 <chr> NA, NA, NA, "Results as on: 2020/12/06 2:12:39 …
$ ...6 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...7 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...8 <chr> NA, NA, NA, NA, NA, NA, NA, NA, "EASTERN CAPE",…
$ ...9 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...10 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...11 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...12 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...13 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...14 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...15 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...16 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...17 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...18 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...19 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...20 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...21 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...22 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...23 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...24 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...25 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...26 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...27 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...28 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ...29 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…